我做了个自我优化的 Dynamic Workflow,还写了篇 Paper 测量它的效果
TL;DR: RHO 把 dynamic workflow 指向 agent 自身:零外部标注、单轮优化,把 SWE-Bench Pro pass rate 从 59% 提升到 78%;拿着验证集标注的基线方法要跑 10 轮、花 3 倍算力才能追平。粘贴一行命令就能在你自己的 Claude Code 项目上运行。
Dynamic Workflow:次时代 Agent 编排技术
Dynamic Workflow 是 Anthropic 在 2026 年 5 月底为 Claude Code 添加的新功能(官方博客《A harness for every task》)。这个功能允许 Claude 通过编写一个 JavaScript 脚本,调度不同的 agent 编排成一个 Harness 来完成任务。这些脚本支持 Agent 的并发执行,以及为每个 Agent 分配不同的隔离环境。
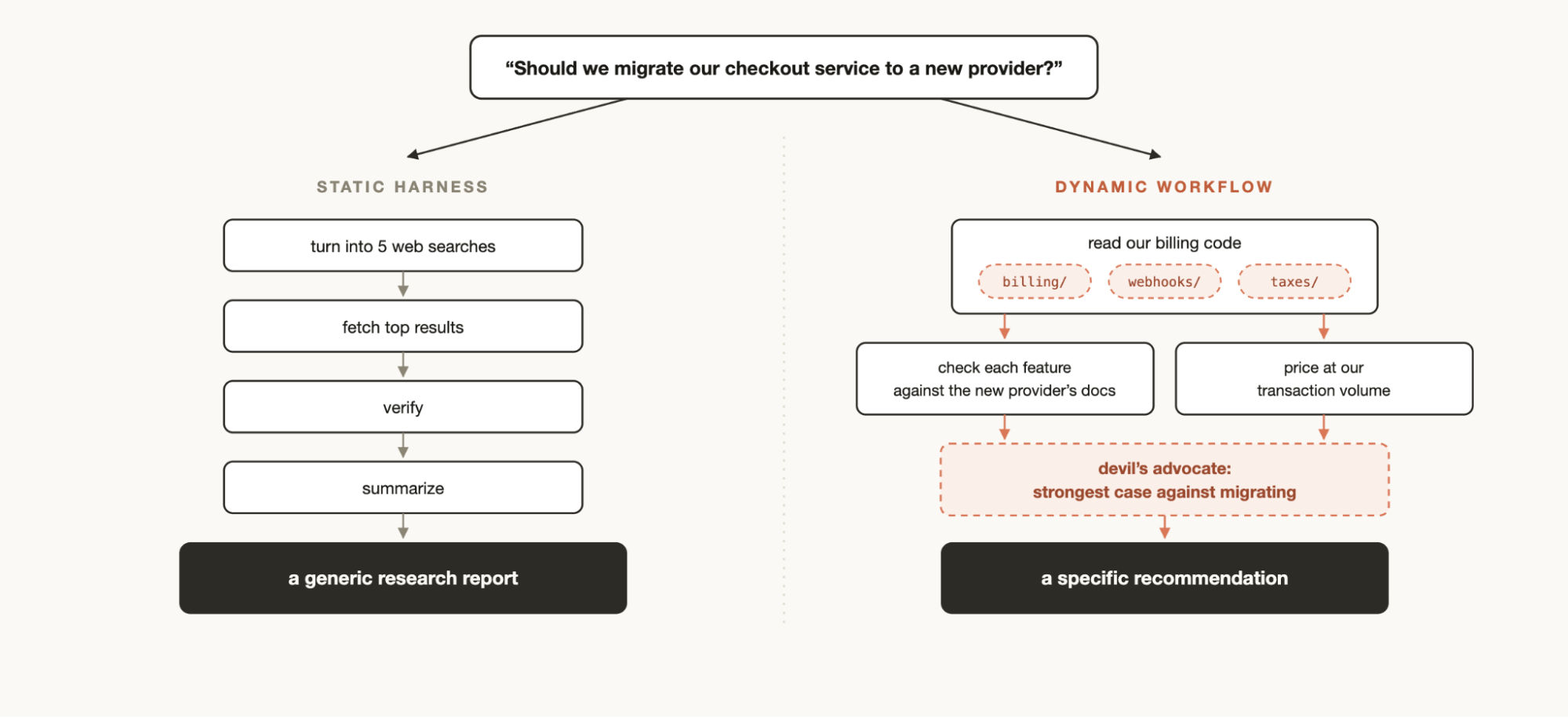
如果只是这么看,我们会有一个非常明显的疑问:Claude 不是本来就支持多 Agent 吗?Claude 自己也可以调度这些 agent 组成特定的工作流啊。
分析 Dynamic Workflow 的实现,我们可以发现它实际上具有两种非常重要的特质:
- 大规模的 Agent 并行:每个 Agent 支持隔离的工作树(worktree),并且可以设置最大并发数量,使得 Dynamic Workflow 一次可以支持比如 100 个 Agent 的并行。
- 完全的上下文隔离:如果是用一个主 Agent 调度所有子 Agent,那么所有子 Agent 的信息都会被主 Agent 看到。但在比如对抗性分析的场景中,我们希望 Agent 之间不要有信息泄露。
当我们充分利用这两种特性时,就可以创造出非常强大的 multi-agent 编排。举一些例子:
- 对抗性验证:让 coding agent 尝试解决一个问题,并让 verifier 验证,进行迭代的循环。
- 头脑风暴:多个 Agent 并行提出 idea,通过一个评分 rubric 进行排序。
- 锦标赛:多个 Agent 在隔离的工作树中独自尝试解决问题,把他们的结果两两竞标,选出最后的优胜者。
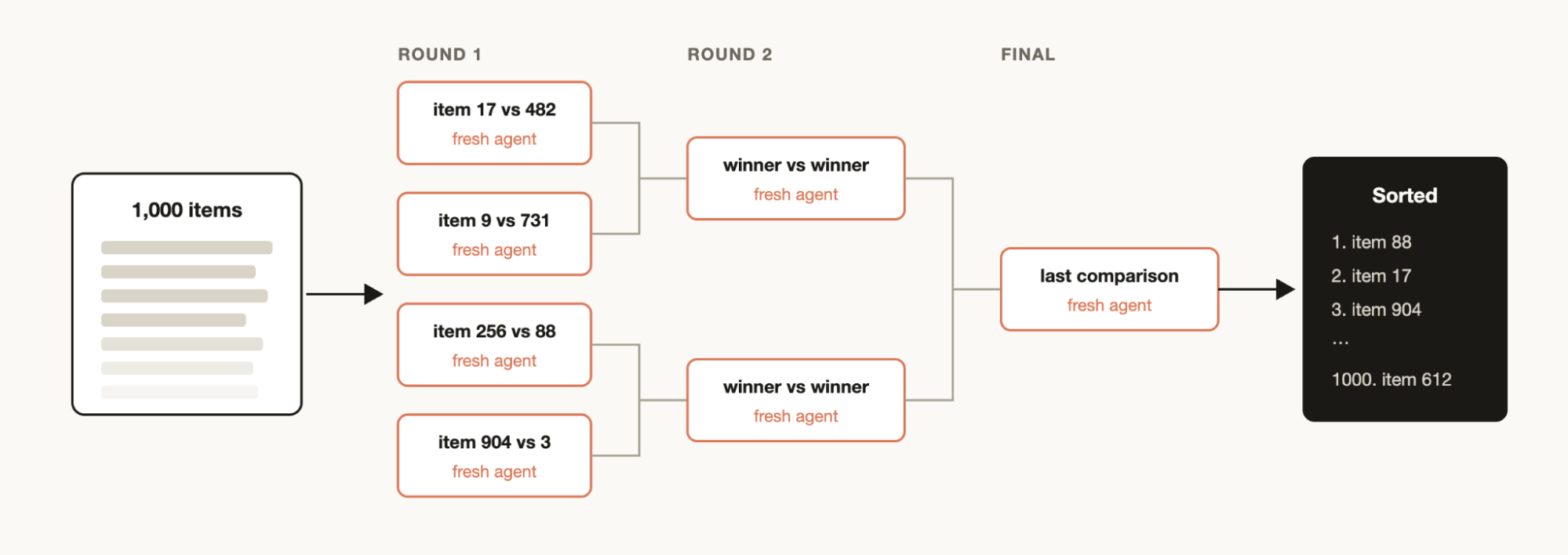
为什么这些编排是必要的?Anthropic 的博客给出了一个很准确的诊断。单个上下文窗口里的 agent 有三种典型的失败模式:偷懒(复杂任务做到一半就宣布完工)、自我偏好(偏爱并放过自己的产出,尤其在让它验证自己时)、目标漂移(上下文被压缩后,原始目标的细节逐渐丢失)。这三种病的共同病根是「规划、执行、评判挤在同一个脑子里」,而 Dynamic Workflow 的并行与隔离恰好是结构性的解药:验证者和生成者互相看不见对方的推理,谁也偏袒不了谁。
有趣的是,博客的示例 prompt 里藏着一个特别的方向:「用 workflow 翻看我最近 50 个 session,挖出我反复纠正它的地方,把高频的写成 CLAUDE.md 规则。」注意,这个 workflow 的对象已经不是某个外部任务,而是 agent 自己的过去,也就是用编排能力让 agent 从自己的经历中学习。这个一笔带过的玩法,恰好是我们最新工作 Retrospective Harness Optimization(RHO) 系统化研究的主题:当你把反思、优化和筛选 agent 并行地编排在一起,Harness 就获得了自我进化的能力。我们还认真测量了它的效果。
把 Dynamic Workflow 指向 Agent 自己
论文是《Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference》(arXiv: 2606.05922),与微软亚洲研究院(MSRA)合作完成。
Agent 的能力很大程度上由它的 harness 决定,也就是那个装着指令、技能和工具脚本的工作目录。任务变了,harness 也应该跟着进化。但已有的优化方法都需要一个带标注的验证集来判断「新 harness 是不是更好」,而真实部署里你手上只有 agent 跑过的一堆历史轨迹,没有任何 ground truth。
没有标注,就只能让 agent 自己当裁判。而这正撞上前面说的那个失败模式:自我偏好。让 agent 在自己的上下文里评判自己的改进方案,它几乎总会说「挺好的」。这就是论文标题里「in the Dark」的含义:没有外部光源,agent 必须在黑暗中摸索着进化,还不能被自己的偏见带偏。
我们的答案是:单个 agent 解决不了的问题,一个精心设计的 workflow 可以。RHO 本质上就是一个指向 agent 自身的 Dynamic Workflow,它把前面介绍的编排模式全部用了一遍:
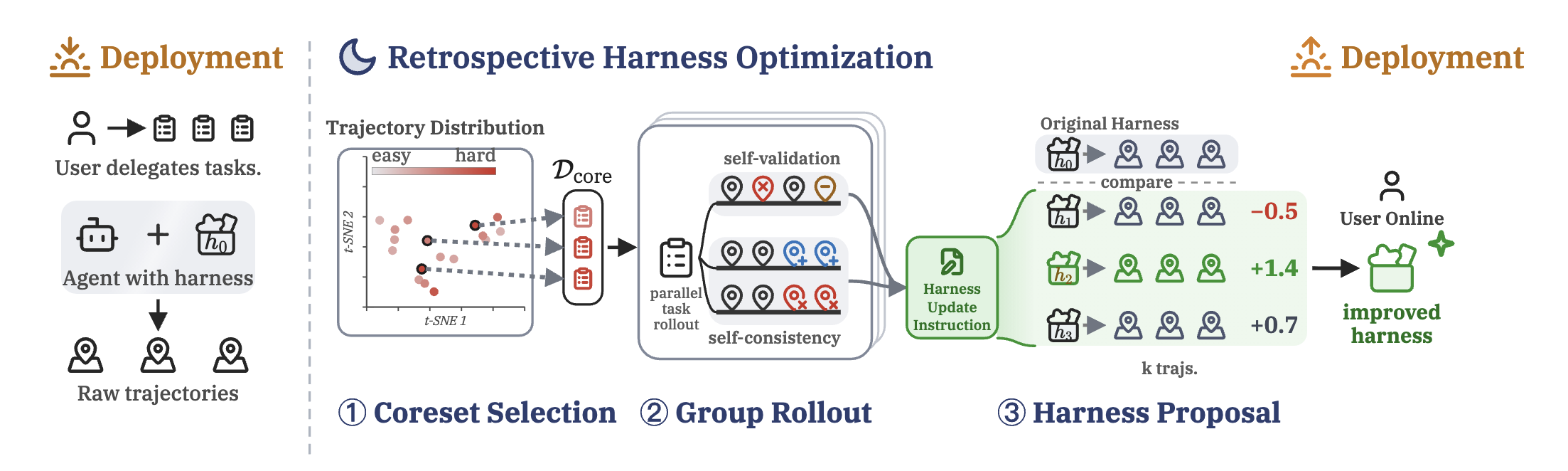
Fan-out:用并行制造「测谎仪」。 RHO 先从历史轨迹中挑出一小批最困难、最多样的任务,然后让 agent 在隔离环境中把每个任务并行重解多次。这一步只有大规模并行加上下文隔离才做得到,因为多次尝试必须互相独立,它们之间的分歧才有意义:几条轨迹给出不同的计划或答案,说明 harness 在这里真的不稳。这是单上下文里永远拿不到的不确定性信号。
对抗性验证:隔离出一个不留情面的审查者。 另一组 verifier agent 在干净的上下文里逐条审查这些轨迹:错误的工具调用、想当然的假设、过早的停止。它看不到解题 agent 的推理过程,只看产出和任务要求,所以不会被「我当时是这么想的」说服。两路信号汇成一份结构化的诊断报告:harness 到底在哪些地方、以什么方式失效。
Generate-and-filter 加锦标赛:让候选 harness 决斗。 拿着诊断报告,多个 optimizer agent 并行提出不同的 harness 修改方案:重写指令、增删技能,甚至现场写新的工具脚本。每个候选 harness 都在全部任务上重新跑一遍,再由隔离的裁判 agent 把它们的轨迹与旧 harness 的轨迹两两对比。只有严格胜过基线的候选才会被部署,打平则维持原状。毕竟自我偏好是有噪声的估计,宁可不改,不可改坏。
整个流程中所有角色都是同一个模型,区别仅仅在于工作区里放了什么:每个算子只看到它该看到的输入。换句话说,RHO 之所以成立,靠的恰恰是 Dynamic Workflow 的那两种特质:并行制造出可对比的独立样本,隔离让「自己评判自己」变得可信。
效果如何?在 SWE-Bench Pro 上,单轮优化、全程零外部打分,pass rate 从 59% 提升到 78%,Terminal-Bench 2 和 GAIA-2 上也有稳定提升。更值得玩味的是和有标注方法的对比:Meta-Harness 拿着验证集标签,在同等算力下只到 62%,要追平 RHO 得跑 10 轮、花 3 倍算力。而进化后的 harness 确实学到了东西:agent 开始主动验证自己的工作,还自己写了新工具来排查它曾经踩过的环境陷阱。它不是往记忆里塞笔记,而是真的改写了自己的工作方式。
这不只是类比:RHO 真的被做成了一个 Dynamic Workflow
仓库里的 .claude/workflows/retrospection.js 就是把论文方法原封不动打包成的一个 Claude Code dynamic workflow,只不过这次挖掘的不是 benchmark,而是你自己项目里已经积累的 session 记录,进化的对象是 Claude Code 原生的 harness:你的 CLAUDE.md、auto-memory 和辅助脚本。一次运行就是一个完整的 RHO 周期(约 40 个 agent):并行消化历史 session → DPP 挑选 coreset → 自我验证 + 跨 session 自我一致性诊断 → 并行生成候选 harness → 在隔离 worktree 中重放探测 → 两两自我偏好打分,平均分为正才应用,应用前自动备份。
在 Claude Code 里粘贴一句话即可体验:
Run the workflow at https://raw.githubusercontent.com/wbopan/retro-harness/main/.claude/workflows/retrospection.js on this project
之后每次重跑 /retrospection 就是新一轮进化,harness 会从你这段时间新积累的真实 session 中继续学习。Codex CLI 用户也有对应的单文件版本 codex/retrospection.py。
写在最后
《A harness for every task》说的是:每个任务都值得一个量身定制的 harness。RHO 想再往前走一步:harness 应该从它经手的每个任务中学习。当反思、优化、筛选这些角色被并行地、相互隔离地编排起来,agent 就能在没有任何人批改作业的情况下持续进化。这可能是 Dynamic Workflow 这类编排原语最有想象力的用法之一。
论文:arxiv.org/pdf/2606.05922 代码:github.com/wbopan/retro-harness 项目主页:paper-rho.wenbo.io